- Research Article
- Open access
- Published:
Social interactive robot navigation based on human intention analysis from face orientation and human path prediction
ROBOMECH Journal volume 2, Article number: 11 (2015)
Abstract
Robot navigation in a human environment is challenging because human moves according to many factors such as social rules and the way other moves. By introducing a robot to a human environment, many situations are expected such as human want to interact with robot or humans expect robot to avoid collision. Robot navigation modeling have to take these factors into consideration.
This paper presents a Social Navigation Model (SNM) as a unified navigation and interaction model that allows a robot to navigate in a human environment and response to human according to human intentions, in particular during a situation where the human encounters a robot and human wants to avoid, unavoid (maintain his/her course), or approach (interact) the robot. The proposed model is developed based on human motion and behavior (especially face orientation and overlapping personal space) analysis in preliminary experiments of human-human interaction. Avoiding, unavoiding, and approaching trajectories of humans are classified based on the face orientation and predicted path on a modified social force model. Our experimental evidence demonstrates that the robot is able to adapt its motion by preserving personal distance from passers-by, and interact with persons who want to interact with the robot with a success rate of 90 %. The simulation results show that robot navigated by proposed method can operate in populated environment and significantly reduced the average of overlapping area of personal space by 33.2 % and reduced average time human needs to arrive the goal by 15.7 % compared to original social force model. This work contributes to the future development of a human-robot socialization environment.
Background
In the recent years, instead of fixed environment like industry, the trend of using robot is shifted to unstructured and public environments such as department store or hospital where humans exist. Same way as computers, many kind of service robots are expected to share and coexist in the same environment as humans to help them with their lives, especially, the kids, elderly and disabled people.
Examples of robots’ expected capabilities in public space are avoiding collisions and providing service to humans. Successful methods to achieve safe, time and energy optimized path to avoiding static obstacles or dynamic obstacles [1] have been achieved for decades.
However, to navigate among humans, robot have to come up with a a higher level model because humans adjust their motions related to how the others (human and robot) move and also expect to interact with a robot. This idea is presented in Fig. 1. Three types of general human motion that a robot is expected to be found in a human environment are as follow:
-
Avoid : humans want to avoid the collision with the robot by themselves.
Fig. 1 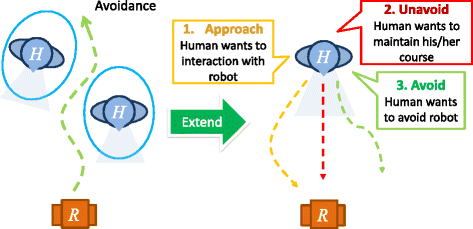
(left) Social Force Model for human collision avoidance (right) Social Navigation Model; during human-robot confrontation, a robot is able to move according to human intention, (1) he/she wants to avoid the collision with a robot by changing lanes, (2) he/she wants to keep moving in the same direction, so the robot has to avoid him/her or (3) he/she wants to approach the robot and interact with it
-
Unavoid : humans do not avoid the robot and expect the robot to avoid them.
-
Approach : humans want to interact with the robot.

How can we enable a robot to navigate according to a situation where humans want to avoid, unavoid or approach the robot?
In this study, we propose a social navigation model (as a unified robot navigation and interaction model in a human environment) which ensure:
-
Safe and socially acceptable (smooth) motion : a robot does not collide with humans and also do not invade human personal space.
-
Human priority : a robot avoids the collision in advance in order to provide a free space to human.
-
Human approach motion : a robot responses to human when he/she approaches robot for interaction.
Usually, a robot and a human move in different directions to avoid a collision. In contrast, they get closer when they intend to interact with each other. These behaviors are verified in preliminary experiment and are modeled as a repulsive and attractive force, respectively. We use face orientation to model these forces, as gaze (face orientation) is considered to be a guide of human attention/intention [2]. Human body pose is considered together with face orientation, to create a modified social force model [3, 4] for human motion prediction. Human avoiding, unavoiding and approaching trajectories are classified within the range where social space and personal space are concerned. With the proposed model, our robot responds smoothly to human motion. Furthermore, the robot is able to behave like a human by providing the human with face orientation in the intended direction before changing its direction when avoiding collisions, and maintaining a proper distance when it was approached by human.
Related work
Many researches [5–9] have addressed the navigation and localizing problems in human environment. On the other hand, many HRI researches have been addressed when humans have already entered a public or social distance such as the research of a robot initializes conversation with users [10], greeting behavior modeling in human-robot conversation [11, 12] and a robot natural greeting behavior based on gestures and utterances [13]. However, a complete model which takes into consideration of the problem of how to make a robot understands and responses to human attention to unavoid, avoid, and approach motion have never been reported.
In this work, we presents a novel concept of unified navigation and interaction model that allows a robot not only to navigate smoothly but also interact with human according to human intentions to avoid, unavoid (maintain his/her course), or approach (interact) the robot, which previous studies did not reported a method to address this problem yet. Therefore, we report related works on aspects of social-aware robot navigation modeling in many scenarios of human environment in this section.
Navigation in humans environment
In the early period of collision avoidance research in a human environment, Murakami et al. [14] discussed the study of collision avoidance between an autonomous wheelchair and human. The wheelchair robot motion planning strategy is based on rough observation of the human face, i.e., whether the human notices the robot. Tamura et al. [9] proposed a collision avoidance model in which a predicted human trajectory is considered as human intention to avoid or unavoid a robot. Glas et al. [7] present the concept of network robotics where the sensors in the environment and social robot are integrated. Many Laser range finders (LRFs) in the environment is used to detect human motion using 3 circle model and track them using particle filter. Multiple robots operated by single operator framwork and user interface is also be proposed.
Lately, the human-robot interaction (HRI) concept is discussed together with the collision avoidance problem. By considering HRI factors (such as proxemics, human gaze, and posture) involved in human path prediction, a robot motion can become more socially acceptable. Most research pays attention to how to integrate these factors via a number of different models [5, 8, 15]. Lam et al. [5] have focused on the harmonious coexistence between humans and robots in navigation tasks. Predefined harmonious rules and sensitive fields of humans and robots were used for robot path planning. Hence, the robot was able to move autonomously to complete a given task and also behave like a human during its operation. Sisbot et al. [8] proposed human-awareness motion planning, which satisfies safety, visibility, and hidden zone criteria.
However, humans do not always intend to avoid the robot. Sometimes, they also want to interact when they need a service from the robot. Therefore, the ability of robots to behave according to human intentions, especially when they want to avoid or approach a robot is important.
Walking side by side
Another aspect of navigation is how the robot can walk side by side with a target human and at the same time avoids the collision with others in the environment. Yoichi Morales et al. [16] presented a computational model which is constructed based on preliminary learning from trajectories of pairs of people when they walk side-by-side. Human-robot mutual utilities were considered in the model when both faced with obstacle in the environment. Ferrer et al. [17] presented a robot companion approach based on social force concept where interaction force to target human is included. The interactive leaning scheme is also proposed for human to adjust robot motion to meet their own comfortableness.
Approaching human
In the social context, a robot does not need to wait for human to interact with them. In contrast, the robot should be able to approach human to give a direct service. Yamaoka et al. [18] proposed a model for a robot to properly adjust its motion when presenting information to human. Satake et al. [19] discussed robot strategies to select and approach appropriate humans in public space based on human trajectories analysis. Shi et al. [20] also proposed a robot behavior model to initiate a conversation with a human.
Following and guiding people
There are situations where a robot have to follow human to target location or to be a leader to guide people around such as leading a human to target location or being a tour guide. Muller et al. [21] proposed an iterative planning model which allow a robot to search for persons that move to the same target location and follow them. Gockley et al. [12] proposed a model for robot to follow person in the direction of the person and evaluated the model to be a human-like behavior. Zender et al. [22] presents people following motion by considering socially acceptable distances from target human, and also provide social cues such as gaze or speech to indicate how the robot tries to maintain following motion. Recently, Garrell et al. [23] proposed multiple robots navigation model that cooperatively guiding group of people in urban area. The prediction and anticipation model is used to predicts the position of a group of human as well as the robot behavior to control people to remain as a group.
Gaze and face pose in navigation
In HRI, many researches enabled robot to use gaze to communicate information about the task to human [24, 25]. Gaze helps establish mutual understanding in the context of dialogue interactions [26].
For navigation, gaze and face pose are important social cues as human use it for signaling each other while they passing each other. Lu et al. [27] proposed a system capable of creating efficient navigation in a corridor by introducing costmap for social navigation and introducing gaze behavior from the robot to the human when robot avoid the collision. Ratsamee et al. [4] modified the social force model by including a force due to face pose so that human-like navigation is achieved with a robot. the robot is able to avoid a collision with a human in a face-to-face confrontation. Human’s proxemic preferences is also related to gaze as it has been shown in Takayama et al. [28] work that the approach distance of human to a robot is based on the robot’s gaze.
Methods
System architecture
A robot that understand human intentions requires several modules to operate together. Figure 2 shows the overall diagram of our proposed system. To obtain the skeleton information [29], we use a RGBD sensor (Kinect). The map of the environment were built in advance based on MRPT framework [30]. Other modules are explained in detail as follow

The overall blocking diagram of proposed system
Face and body pose estimation
The face orientation and body pose of the human during motion are estimated according to our previous work [4]. The human tracking and body pose is estimated based on the upper body appearance of skeleton information from Kinect sensors using extended Kalman Filter with the accuracy of 5-cm. The method is robust to partially occlusion and be able to track multiple people. Based on the The face pose is detected and tracked with maximum 6 degree RMS error with in the range up to 5 m. If the failure occurred due to complete occlusion, the system can reinitialize itself automatically.
Personal space
We also take into consideration the concept of personal space [31], which prevents uncomfortable feelings when humans plan to avoid or interact with a robot. Lam et al. [5] discuss different types of personal space in different situations e.g. egg-shaped personal space while moving. Scandolo et al. [32] use personal space in their social cost map model for socially acceptable path simulation. Context-dependent social mapping [33] was proposed as an effective and adaptable human spatial interactions between groups of human.
In this study, the personal space during human motion according to time step, t, is modeled as an ellipse:
where \(\textbf {R} = \left [ {\begin {array}{cc} {\cos ({\vartheta _{t}})}&{ - \sin ({\vartheta _{t}})}\\ {\sin ({\vartheta _{t}})}&{\cos ({\vartheta _{t}})} \end {array}} \right ]\) is the rotation matrix. x(θ rt ) and y(θ rt ) are the points on the personal space distributed by angle, θ rt (varying from 0-2 π). m i and m a are the minor and major axe which derived from m a =c x +v x and m i =c y +v y where c x and c y are personal space constant on x and y axis respectively. The direction of the personal space is estimated by the face orientation, 𝜗 t .
We utilized adaptive ellipse-shaped personal space because giving a human with a long and clear space in front of humans while they are moving with a certain speed provide both mental and physical safety [5]. However there is a trade of between efficiency and safety. When there are many pedestrians in the environment, too wide personal space leads to make a robot easily falls into local minima (deadlock problem [34, 35]) which is the situation when robot can not move. To avoid this problem, the minor axis of personal space should be more narrow compared to major axis so that the flow of humans and also robot can penetrate smoothly. The result of smooth and unfreezing navigation will be discussed in Simulation Section.
Human state
The characteristics of a human which are applied to modified social force model for motion prediction, are stated as
where (x t ,y t ) are the x and y position of the human and v t is human velocity. ρ t and 𝜗 t are the body pose and face orientation angle with respect to the world coordinate. The calculated velocity of human, current robot position, goal position, and personal space are input to the social navigation model to estimate robot velocity and its face orientation.
Learning from human interaction
Humans treat technology (that similar to their common understanding) in the same way they treat other humans [27, 36]. If the robot do not behave similar to their common understanding, the human will confuse by the robot’s behavior and end up with failure in human-robot interaction. Therefore, learning how humans interact between each other is important toward smooth interaction between human and robot. In order to extract the key interaction to build the a social navigation model, we observed humans motion and behavior in preliminary experiments while they were approaching and avoiding each other.
Preliminary experiment setup
For public space such as department store or hospital, the robot is mainly expected to meet general people that a robot does not know in prior same way as when shopping mall or hospital staff meets new customer in daily work. Hence, the main focus is how service robot responses smoothly to unfamiliar people that robot meet in public space. Our main goal of this experiment is to analyze how humans who do not know each other avoid, unavoid or approach with each other in public space and make use of that knowledge to create social navigation model.
There were 16 participants who have no prior experience working with robots. All participants have not known each other before. Participants were the Osaka University student. The ages are ranged from 19 to 30 (mean = 23, SD = 3.28, median = 22). Twelve participants (75 %) were male, and all participants were Asian (50 % are Japanese and 50 % are Thai).
Two tracks were prepared: face-to-face confrontation (left side of Fig. 3(b)) and different lane passing-by situation (right side of Fig. 3(b)). Two people from 16 participants were randomly paired. All pairs of participants performed both tracks. For each pair of participants, two tasks, approaching and avoiding, were conducted. Five trials were performed in each task. In each experiment, only a participant decides to approach, unavoid or avoid other human. The human position, body pose, face orientation and relative distance were tracked simultaneously by 2 kinect sensors at the start/goal line. The personal space of the human was adapted using face orientation. The moment when human is going to change from one state to another state (for example avoiding to approach) were marked by the participants as a ground truth.

a Graphical display of how humans avoid each other and b Preliminary experiment setup of (left) face-to-face confrontation and (right) different lane passing-by
Preliminary experiment results
The graphical results at the moment of avoiding and approaching are presented in Fig. 4. Obviously, the overlapping area of the personal space between humans clearly distinguishes these two behaviors. During an avoiding motion (upper graph in Fig. 4), the participants do not have any interest to interact with each other. Therefore, there is a small overlapping area of the personal space during motion. As presented in Fig. 5(a), the average overlapping area during the avoiding motion is found to be only 12.5 c m 2. On the other hand, there is an average overlapping area of 65.24 c m 2 while participants were approaching each other.

The results about personal space overlapping in the case of (upper) avoiding and (lower) approaching case

a Total proxemic overlapping area and b total number of overlapping face orientation
The average number of overlapping face orientations between participants was also be investigated. Fig. 5(b) shows a comparison of the total number of overlapping face orientations when the participants avoid or approach each other. In an approaching case, the average overlapping face orientation is found to be 13.11 times. In contrast, the average overlapping face orientation when participants avoid each other is only 5.11 times.
The results about the overlapping of personal space and face orientation confirmed a repulsive and attractive force acted between participants while they avoided or approached each other. The duration of overlapping face orientation between humans is directly related to how much humans were going to approach each other. We use these results to develop the social navigation model. Note that the variance of overlapping face orientation in the avoiding case was high, because it was hard for humans to predict whether he/she wants to avoid or unavoid the other during face-to-face confrontation. This information prompted us to create 2 ranges of consideration in the social navigation model to avoid the confusion that might happen in face-to-face confrontation with human.
The average range of avoidance or approach (\(D^{H}_{\textit {interactive}}\)) and the appropriate distance for interaction (d interact ) between humans are found to be 2.18 and 0.69 m respectively. Because the maximum walking speed of a human in this experiment was 1.44 m/s, we set \(D^{R}_{\textit {interactive}}\) to be from 0.45 to 2.5 m (our system runs at an average of 18 Hz). Therefore, \(D^{R}_{collision-free}\) was set from 2.5 to 4 m. We set c y and c x as 0.5 and 0.2 m respectively. These ranges correspond to results obtained through the study of proxemics [28, 31] since they are within the range of personal space to social space.
Robot motion planning based on human intention
As presented in Fig. 6, we build Modified Social Force Model (MSFM) and Social Navigation Model (SNM) based on the fundamental model of Social force concept. To classify human motion (avoid, unavoid and approach) correctly, we integrate the high-level perception of humans, including body pose, face orientation and personal space during motion to a modified social force model. For a robot to smoothly respond to human motions, we use the social navigation model in motion planning.

Two different model for The overall blocking diagram of proposed system
Modified social force model (MSFM)
We employ the social force model [3, 37] to predict human motion. A human, H i , is modeled as a particle i with a mass, m. He/she walks with an intended velocity, v, in a desired direction, d. In the social force model at each time step, their motion is described by the superposition of 2 types of force:
Attractive force to the goal
With an internal motivation to the goal, a human adapts his/her velocity v to an intended direction by
where τ r is the rate of change (relaxation time) required by agent (human or robot) for adapting the current velocity to the intended direction. We use the body pose of a human as a representation of the intended direction for human motion prediction [29].
Repulsive force from others
Based on the influences from the object and the other humans present in the environment, a human has to adapt his/her direction according to these disturbances, which are modeled as the repulsive force between human, F human and object, F object. Both F object and F human are the result of a combination of social repulsive forces, f social , and physical repulsive forces, f physical . A physical repulsive force f physical is formulated as
where k ph represents the physical constant of the physical force. A can be a person/an object encountered in the environment. Other humans and objects are modeled as particles with radii r i and r A . d i,A is the distance between the two entities. r i,A is the summation of their radii. Vector v i,A indicates the direction from A to H i . Social repulsive forces are described as :
Influences from social repulsive forces are limited to the field of view of humans, therefore the anisotropic term, \(w(\gamma)= {\lambda + (1 - \lambda)\frac {{1 + \cos ({\gamma })}}{2}} \), defined by constant, λ, is introduced in the equation. γ is the angle between other humans and intended direction. k so is the magnitude and s A is the range of the force.
Modification based on Face Orientation
Typically, face orientation points to human intention/attention [2]. In a face-to-face confrontation, if humans want to talk to the person who walks pass by, they will look at him as a sign to start the conversation [2]. On the other hand, if humans do not know each other or do not want to start a conversation, they will look in the direction that they want to go to show their own intentions. This is a natural human mechanism and is modeled as a social force based on face orientation, F face:
FS refers to the strength of the force. The exponential growth of the force depends on the range of the force, s A , distance, d i,A , and the sum of their radii, r i,A . The term v i,A is the face orientation vector of H i related to A, and describes the orientation of the force. The angle between the face orientation vectors is denoted by θ fs . Therefore, the resulting force is modeled as :
We use v to predict the human path which is derived from
in every time step. An illustration of all forces is shown in Fig. 7(a).

a The modified social force model, b collision-free and interactive range, c avoid and unavoid motion classification, and d direction of the force due to face orientation depends on the probability of approaching or avoiding derived, from face orientation
Social navigation model
The Social Navigation Model (SNM) is developed from the concept of social force model. In SNM, the human’s intentions to avoid, unavoid or approach a robot are determined based on face orientation and human predicted path [38].
As presented in Fig. 7(b), there are two types of range to be considered; \(D^{R}_{collision-free}\) is the range where a robot considers whether humans intend to avoid or unavoid a robot and \(D^{R}_{\textit {interactive}}\) is the range where a robot considers whether humans intend to approach or avoid robot. The values of all parameters in this section are discussed in a preliminary experiment with humans.
Collision-free range
\(D^{R}_{collision-free}\) is considered when a human and a robot are in the same lane only. We use the concept of avoiding or unavoiding probability based on predicted path [9], as presented in Fig. 7(c). Next position (p τ) on the human predicted path is used as a reference. d τ, which is the distance from p τ to \(Tr^{\tau }_{(un)avoid}\) (avoid or unavoid trajectory) is derived as:
Hence, the total distance, \(d_{_{\textit {total}}}^{\tau }\), is defined as
We can find the probability of a human performing an unavoidance motion \(\mathrm {P}_{\textit {unavoid}}^{\tau }\) or avoidance motion \(\mathrm {P}_{\textit {avoid}}^{\tau }\) by
If \(\mathrm {P}_{\textit {avoid}}^{\tau } > \mathrm {P}_{\textit {unavoid}}^{\tau }\), the robot remains in the same lane. The robot changes the lane when \(\mathrm {P}_{\textit {avoid}}^{\tau } < \mathrm {P}_{\textit {unavoid}}^{\tau }\). As a result, in both cases, the robot and human will be in a different lane. This robot behavior is safe and comfortable for humans in a passing by situation, since humans prefer a bigger distance and they feel more relaxed when the robot leaves the way open from them [39].
Interactive range
Next, the robot starts considering human intention to approach in the range of \(D^{R}_{\textit {interactive}}\), which is derived as
where \(D^{H}_{\textit {interactive}}\) is the range that humans normally start avoiding each other. v r,h is the relative velocity of the human with respect to the robot.
Within this range, the robot considers both the predicted path and the face orientation as signs of human intentions. The visualization of this force is presented in Fig. 7(d).
We consider the duration of face orientation towards the robot from the first observation time to time τ as \(f_{_{\textit {robot}}}^{\tau }\), and the duration of the face orientation to others as \(f_{_{\textit {other}}}^{\tau }\). Hence, the total duration is defined as
From the duration of face orientation towards any target object, we define the probability that the human will approach (\(\text {Pr}_{\textit {approach}}^{\tau }\)) or avoid (\(\text {Pr}_{\textit {avoid}}^{\tau }\)) at time, τ, based on the following two equations :
Note that \(d_{\textit {unavoid}}^{\tau }\) is treated as \(d_{\textit {approach}}^{\tau }\) and ξ is the normalized factor. We use this condition to adapt the direction of the force \(\textbf {F}^{face}_{\textit {interactive}}\) in the SNM. Different from the MSFM applied to human, the force due to face orientation applied to the robot is derived as
where the force can be adapted as
-
Attractive force, FS : when \(\text {Pr}_{\textit {approach}}^{\tau } > \text {Pr}_{\textit {avoid}}^{\tau }\)
-
Repulsive force, −F S: when \(\text {Pr}_{\textit {approach}}^{\tau } < \text {Pr}_{\textit {avoid}}^{\tau }\)
If \(\text {Pr}_{\textit {approach}}^{\tau } > \text {Pr}_{\textit {avoid}}^{\tau }\), the subgoal of the robot is created in front of the human with an appropriate distance (d interact ) for the human to feel comfortable when interacting with the robot. The robot remains in the same lane when \(\text {Pr}_{\textit {approach}}^{\tau } < \text {Pr}_{\textit {avoid}}^{\tau }\). In case of the approach case, when the human behavior is confirmed, the subgoal will be created in front of human. Since the robot sense human locally with sensor on the robot, when they are many people. Safety will be a main concern for the robot. Even the person in front of robot want to interact but the robot might have high change to collide with another person, the robot will stop the motion and wait for the target approach human. Note that the robot is able to interact with person one by one. In case there are more than 1 person want to interact with the robot, the closest person to robot will be targeted for interaction.
Results and discussion
In this section, Human-robot experiments were conducted to analyze and verify our proposed method. We used a one-way repeated-measure analysis of variance (ANOVA) to analyze errors.
Experiment setup
An Enon humanoid robot (Fig. 8(a)) with a Kinect sensor placed on the head (1.8 m above the ground) was used in the experiment. The robot size is 0.30 in width and 1.80 height. Experiments were conducted in a common human-robot coexisting situation such as a corridor or an office. Participants in this experiment are the same group of people who participated in preliminary experiment. The experiment setup was the same as Fig. 3(b) where participant have equal chance to start at the initial point on the same lane or different lane. For each participant, we conducted 15 experiments each on avoid, unavoid and approach cases. For approaching case, participants were told that they would be able to approach the robot to ask for information or utilize the touchscreen on robot body to search for information. To evaluate the proposed model, we used the criteria [4, 9] presented in Fig. 8(b). With this criteria, the result obtained with the proposed method can be classified as:
-
Fail refers to the case when the robot collides with a human.
Fig. 8 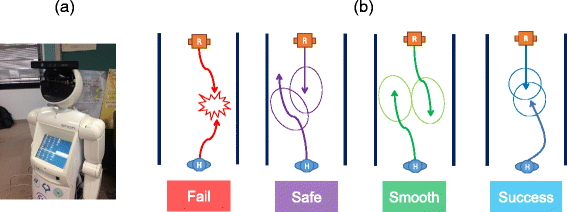
a Enon robot and b the graphical idea used to describe possible cases during navigation. If the robot collides with a human, we consider it as a ‘Fail’ case. A ‘Safe’ case is when the robot can avoid a human but there are high overlapping regions of personal space. The robot achieves ‘Smooth’ collision avoidance when it can avoid a collision with the human and also has a small overlapping region of personal space. Lastly, a ‘Success’ case refers to the situation when the robot successfully maintains an appropriate distance when it is approached by a human
-
Safe is when the robot can avoid a human but there are high overlapping regions of personal space.
-
Smooth is when the robot can avoid a collision with the human and also has a small overlapping region of personal space.
-
Success refers to the situation when the robot successfully maintains an appropriate distance when it is approached by a human.

If the overlapping area between robot and human is less than or equal to the average overlapping area during avoiding motion between human and human in preliminary experiment, we consider it as a Smooth case, otherwise it is classified as a Safe case. After the experiment, we ask the participants to answer the post questionnaires. The post questionnaire was mainly concerned with participant’s opinion regarding to their experience in the experiment with robot compared to human (preliminary experiment) and overall participant experience. Five points Likert scale [40] was used to evaluate the following questions:
-
Q1: I felt more relax encountering the robot on the corridor compared to human.
-
Q2: I felt that the robot always provide me the way in face-to-face confrontation.
-
Q3: I felt that the robot understand my attention when I plan to maintain my path (unavoid).
-
Q4: I felt that the robot understand my attention when I plan to avoid it.
-
Q5: I felt that the robot understand my attention when I approach it.
Parameter optimization
MSFM and SNM parameters were determined from the dataset of avoid and unavoid trajectories from preliminary experiment. Parameters in SNM is determined from all trajectories from preliminary experiment. We have compared a ground truth of observed position, face pose of persons from preliminary experiment, t r gt (t), with the predicted position from SFM, MSFM and SNM, t r p (t). Genetic Algorithm [41] for parameter optimization is applied in order to minimizing the following objective function;
where N tr is total number of trajectories. Table 1 presents the parameters learned after applying the optimization process. As a comparison, we compared our optimized parameter set with the study of [37]. Our learned parameters for SFM, MSFM and SNM are slightly different because we learn from human-human interaction in many different scenario such as avoid, unavoid and also approach trajectories of human which does not exist in other datasets of related works of Human-Human interaction using only SFM [37, 42]. Note that, the force due to face pose parameter is less than the social repulsive force parameter. The force due to face orientation has a relative effect on the social repulsive force. A high value of force due to face orientation makes the human tracking path fluctuate, while a low value yields no effect. According to [37], the influence of the obstacle in the environment and other humans are different therefore, we have 2 sets of parameter for obstacles \(\left (k_{(ph,so)}^{o},s^{o}\right)\) and humans \(\left (k_{(ph,so)}^{h},s^{h}\right)\).
One to one interaction results
This section we presented the evaluation results of One to One Interaction between a human and a robot. Figure 9 shows the percentage of success rates of avoiding, unavoiding and approaching cases. We achieved a 85 % success rate in an approaching case and a 90 and 92 % success (smooth + safe) rate in the avoiding and unavoiding cases respectively. ‘Fail’ case was found to be below 10 % which occurred sometime when the system failed to track face and body pose.

The success rate of robot motion planning in the case of avoiding, unavoiding and approaching case
All participants were able to complete the post questionnaire. Figure 10 shows the analysis of the post questionnaire using 5 points Liker scale. Most participants mention that they feel relax when facing robot the robot compared to human (Q1) especially person who did not want to avoid robot mentioned that they felt relaxed because the robot did not block their way and they also noticed that the robot turned its face away before trying to avoid them (Q2,Q3).

An analysis (mean and standard deviation) of the answer of questionnaires (Q1-Q5) from all participants
When participant intend to unavoid the robot, the robot always change the lane in advance (Q4) which reduce the confusion that usually happened in face-to-face confrontation between humans. In the approaching case, participants mentioned that the robot moved to them smoothly and maintained a proper distance from them allowing them to use the touch screen on the robot (Q5). This suggestion confirmed that the proposed model achieved all 3 possible cases of human behavior.
One to many interaction results
To demonstrate the robustness of our proposed model, we extended the experiment in the previous section by perform the experiments in the environment where a robot has to perform different tasks continuously.
Experiment 1 : Figure 11 shows the situation where the robot has to perform collision avoidance continuously. In this case, none of the participants wanted to avoid the robot (i.e. they expected the robot to avoid them). The result shows that the robot was able to estimate the path of the humans one by one and avoid both of them. Both avoiding motions also satisfied the smooth collision avoidance requirement.

Experiment 1: the experiment result shows that the robot was be able to avoid the collisions continuously when humans do not intend to interact with the robot and expect the robot to avoid the collisions
Experiment 2 : Another experiment was performed in an office environment as presented in Fig. 12. The robot observes the first person and understands his/her intention to unavoid the robot within the collision-free range, therefore the robot turns its face toward the opposite direction, and steers away from the human. Afterward, a second person is observed. As opposed to the first person, the second person intends to interact with the robot and provides the proper face orientation. Using the proposed model, the robot approaches the human and maintains an appropriate distance.

Experiment 2: The experiment results show that the robot was able to avoid the collision with the first person and then interact with the other person based on an analysis of the human face orientation based on the proposed model. Furthermore, the proxemic rule about the personal space estimated by face orientation was also preserved because of a smaller overlapping region during avoidance. Finally, the robot maintained the personal distance when interacting with humans
Experiment 3 : This experiment presented the scenario when 2 persons are walking together and notice the robot on the corridor. The experiment result in Fig. 13 shows the robot and the human maintains their course. Both Human trajectories and face pose were observed. Even the human looks at the robot at the interactive range, they don’t show any intention to interact with robot via the trajectory. Only force due to face pose alone are not sufficient to change the robot behavior from maintaining course to interact with the person. Hence, the robot remains on the their own track until the 2 persons pass them.

Experiment 3: The experiment result shows the robot and the human maintains their course. The robot observes human trajectory and face pose while moving. Even the human looks at the robot at the interactive range, they don’t show any intention to interact with robot via the trajectory. Hence, the robot remains on the their own track
Experiment 4 : The experiment result in Fig. 14 shows the robot avoid humans at the first place as the humans remain on their track. Even the robot is in different lane, when the human shows the intention to interact with robot via both face orientation and trajectory with in the interactive range, the robot approaches humans and remain at the proper range. For the interaction, the robot can serve human one by one therefore, the closest person will become a target for robot to interact.

Experiment 4: The experiment result shows the robot avoid humans at the first place. Since the human shows the intention to interact with robot via both face orientation and trajectory with in the interactive range, the robot approaches humans and remain at the proper range
Furthermore, as two or more persons might have no interest in the interaction with the robot and also block all robot possible paths, the robot have to stop until the human give it a possible path to continue the task. This situation is called deadlock problem and as discussed in many researches [5, 17] that we either develop robot behavior to request the path from human in case of emergency or robot should wait until the possible path is available.
Simulation
We developed the simulation in order to evaluate the performance of the SNM in populated environments. as presented in Table 2, under simulation, we compare how 3 different pairs of models applied to robot and humans which are Pair 1: SNM and MSFM, Pair 2: MSFM and MSFM, and Pair 3: SFM and SFM would affect smooth collision avoidance and interactions between people and the robot.
Simulation setup
Three different scenarios, presented in Fig 15, were prepared which are the Open Space where there is no obstacle, the Common Hall and the Door Way where the bottleneck behavior are expected. To evaluate human and robot collision avoidance and interaction, we first performed the simulation in Open Space environment (20 by 20 m) where there is no obstacle. Secondly, we perform the simulation in a 20 by 20 m common hall scenario. This scenario represents the realistic social space where there are a lot of obstacles and people are passing by. Thirdly, we challenge our proposed SNM in the door way (with a bottleneck in the middle) scenario. Pedestrians are moving in opposite directions and pass through a bottleneck, i.e. a narrowing of the passageway.

Simulation result of three scenarios which are a Common Hall c Open Space and e Doorway where the bottleneck is expected. The second column presented the overlapping area corresponded to each scenarios which are b Common Hall d Open Space and f Doorway. We compared three different models which are (red) pair (1): SNM and MSFM, (green) pair (2): MSFM and MSFM, and (blue) pair (3): SFM and SFM
We performed the simulation for more than 30,000 experiments with the variation of number of pedestrians and the initial position of each pedestrians and robot. The example of the simulation scenario is presented in Fig. 16. To evaluate how robot navigated and interacted among crowds, two group of pedestrians (represented in blue and green color in Fig. 15) are assigned move toward two destinations, which are leftmost and rightmost on the map. In each simulation, robot will be assigned randomly to one group of pedestrian. These assignments are typical of the kind of navigation and interaction a person unfamiliar with robots is likely to encounter in uncontrolled environments in the future, such as department store and hospitals, where a robot have to move toward the same goal as some people and may encounter another people with no prior explanation.

The example of the simulation result in the Common Hall (left) the beginning of simulation (center) at the middle part of simulation (right) the end of the simulation
According to human density metric [35], we varied the human density in each scenario from low density of 0.1 to high density of 1 p e r s o n s/m 2 (a shoulder to shoulder crowd). Pedestrians will be assigned equally with one behavior from three behaviors (avoid, unavoid or approach represented by square, star and circle mark respectively in Fig. 15) when he/she met robot. We assigned the same face pose pattern to each agent that we learned from the preliminary experiments. The robot sensed the human locally within its field of view.
Safety is our main concern therefore we not allow the robot to collide with either walls or people. If the robot path and predicted path of pedestrians leaded towards collision within its personal space (1.2 m), then the robot was emergency stopped and give a way to pedestrian. Pedestrians are allowed to reduce the relaxation time and personal space so that pedestrian can escapes from when freezing problem happened in high density scene.
The simulation run on a PC (E5420 2.50 GHz Xeon CPU, 4096M RAM, NVIDIA Quadro FX 1700 graphic card). The processing time and the evaluation process varies between 10 seconds to 300 seconds, depending on time and the number of pedestrians. All data processing is performed using MATLAB. We evaluated the smoothness which refer to the overlapping area of personal space, traveling time of human to arrive goal and the percentage of successful interaction when human approached robot.
Simulation results
Overlapping space
The overlapping area of personal space is represented in the range of [0−1] as we used the maximum overlapping area of each pair of models for normalization. The second column of Fig. 15 shows the overall overlapping area of the different methods with respect to the density of pedestrians in the scene. In all possible case, under 0.1 p e r s o n s/m 2, their is no overlapping error since each agent can have many possible paths to arrive the goal. Overlapping of personal space grows linearly with crowd density when the human density goes over 0.2 p e r s o n s/m 2.
As a comparison between scenarios, the average overlapping area of personal space in Open Space is lower than Common Hall scenario. Many existing obstacles presented in the Common Hall environment make robot and each agents choose the paths where high overlapping of personal space can not be avoided. However, in all the cases, SNM model guaranteed the safety since there is no collision caused by robot occurred even in 1 p e r s o n s/m 2 case, because the robot aim to give the way to the pedestrians first and navigate to the goal when the path clear of pedestrian. In case of Door Way, overlapping area were abruptly increased when densities above 0.35 p e o p l e/m 2. This was a result of the freezing problem at the door way, many agents can not move at the bottleneck which yields the accumulation of overlapping area of personal space. Based on the adaptive of relaxation time when many agents can not move, pedestrian is allowed to have narrow personal space which help them relax the stress at bottleneck and can be able to pass each other.
The average overlapping area of pair (1) SNM and MSFM is significantly lower than (2) MSFM and MSFM and (3) SFM and SFM by 21.1 and 33.2 % respectively. Clearly, using SNM highly increases the smoothness of navigation even in populated environment.
Time to achieved the goal
The comparison of time to achieve the goal of human in each scenario is presented in Fig. 17. Because of the obstacles in the environment, time to achieve the goal of human in Common Hall is averagely higher than in Open Space scenario. Even the time to achieve the goal of robot with (1) SNM and MSFM take more time compared to (2) MSFM and MSFM and (3) SFM and SFM to achieve the goal, the time pedestrians used to achieve the goal of pair (1) SNM and MSFM is lower than (2) MSFM and MSFM and (3) SFM and SFM since the robot sometime has to stop moving forward and give the way to unavoid pedestrians at collision-free range, especially, when the human density was higher than 0.5 p e r s o n s/m 2. The pedestrians are able to pass the robot with much greater ease and ends up arrive the goal quicker as a result. On average, the time to achieve the goal of human of pair (1) SNM and MSFM is lower than (2) MSFM and MSFM and (3) SFM and SFM by 10.14 and 21.23 % respectively in case of low human density (less than 0.3 p e r s o n s/m 2) and 6.15 and 9.3 % respectively in case of high human density (more than 0.7 p e r s o n s/m 2).

The result of time to achieve the goal of human of each pair of models in each scenarios which are a Common Hall b Doorway and c Open Space
Bottleneck
In our door way scenario, pedestrians have to move in opposite directions passing through narrowing door way (bottleneck) as presented in Fig. 15(e). When the human density was higher than 0.35 p e r s o n s/m 2, crowds of pedestrian will form up on both sides of the bottleneck, trying to push through the doorway. Afterward, an oscillatory flow of small groups of pedestrians will pass through one direction, making a space for another small group on the opposite side to pass through each other, and so on.
We want to see how robot with (1) SNM and MSFM responsed in this challenging scenario. Base on the decision to change the lane in collision-free range, the robot aim to move to free space where there is no people which usually end up at the left or right corner from the door way. Essentially, the robot waited until the density at the door way was low enough (less than 0.35 p e r s o n s/m 2) to navigate to the goal. This is the process to ensure safety and smoothness and also show that our robot can survive in such a difficult situation.
Interaction
As presented in the experiment setup, we assigned 33 % of pedestrians with approach behavior in each simulation. The success rate of robot that interaction with human is presented in Fig. 18. We can see that the robot having no problem interact with approach pedestrians under human density of 0.3 p e r s o n s/m 2. However, in high density environment, where the pedestrian are expected to come from many direction, the robot main priority is the avoid the collision (safety) therefore during the avoiding motion the robot have to skip the interaction with approach pedestrians.

The result of interaction achieved in each scenario
In door way case, robot usually move to the left/right side of the wall therefore, the approach pedestrian who escape from the crowd can interact with the robot easily therefore the interaction can be done more successfully compared to Open Space and Common Hall scenario.
Conclusion
We proposed a novel social navigation model that allows a robot to both navigate smoothly in a human environment and behave properly when human want to maintain course (unavoid) or approach robot for interaction. Human behavior is determined based on human face orientation and predicting human path using a modified social force model. From preliminary experiments, we realized that avoiding and approaching behaviors corresponds to repulsive and attractive forces between two agents and we use this evidence to create our proposed model.
Experiments were performed in social scenarios, such as when walking persons encounter a robot in a corridor or social space. By taking into account the effect of face orientation and personal space during motion planning, not only does the robot achieve safe and smooth collision avoidance, but it is also able to achieve approaching behavior. Using the proposed model, the robot was able to preserve the laws of proxemics while avoiding or interacting with the human with a success rate of 90 %. The simulations in populated environment show that robot can navigate smoothly without collision by reducing the average of overlapping area of personal space by 33.2 % compared to original model. Furthermore, the robot motion is considered to be time efficient for human since the robot path do not delay humans when they travel to the goal. On average, the proposed model reduced the time human need to travel to the goal by 15.7 % compared to original model. Furthermore, the interaction with human was achieved with more than 70 % even the human density is up to 0.5 p e r s o n s/m 2.
In this study, the parameters were systematically optimized by Genetic algorithm from our set of participants. All parameters and human characteristics have to be reconsidered for other groups of people from a different culture or context.
References
Zhu DQ, Yan MZ (2010) Survey on technology of mobile robot path planning. Control Decis 25(7): 961–967.
Heylen D (2006) Head gestures, gaze and the principles of conversational structure. Int J Humanoid Robot 3(03): 241–267.
Helbing D, Molnar P (1995) Social force model for pedestrian dynamics. Phys Rev E 51(5): 4282.
Ratsamee P, Mae Y, Ohara K, Takubo T, Arai T (2013) Human-robot collision avoidance using a modified social force model with body pose and face orientation. Int J Humanoid Robot 10(01). doi:10.1142/S0219843613500084.
Lam CP, Chou CT, Chiang KH, Fu LC (2011) Human-centered robot navigation—towards a harmoniously human–robot coexisting environment. IEEE Trans Robot 27(99): 1–14.
Kanda T (2007) Field trial approach for communication robots In: IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), 665–666.. IEEE, Jeju.
Glas DF, Satake S, Ferreri F, Kanda T, Hagita N, Ishiguro H (2012) The network robot system: enabling social human-robot interaction in public spaces. J Human-Robot Interact 1(2): 5.
Sisbot EA, Marin-Urias LF, Alami R, Simeon T (2007) A human aware mobile robot motion planner. Trans Robot 23(5): 874–883.
Tamura Y, Fukuzawa T, Asama H (2010) Smooth collision avoidance in human-robot coexisting environment In: International Conference on Intelligent Robots and Systems, 3887–3892.. IEEE, Taipei.
Rich C, Ponsler B, Holroyd A, Sidner CL (2010) Recognizing engagement in human-robot interaction In: Human-Robot Interaction (HRI), 2010 5th ACM/IEEE International Conference on. doi:10.1109/HRI.2010.5453163.
Li S, Wrede B, Sagerer G (2006) A dialog system for comparative user studies on robot verbal behavior In: Proceedings - IEEE International Workshop on Robot and Human Interactive Communication, 129–134. doi:10.1109/ROMAN.2006.314406.
Gockley R, Forlizzi J, Simmons R (2007) Natural person-following behavior for social robots In: Proceedings of the ACM/IEEE International Conference on Human-robot Interaction, 17–24.. ACM, New York, NY.
Yamamoto M, Watanabe T (2004) Timing control effects of utterance to communicative actions on embodied interaction with a robot In: RO-MAN 2004. 13th IEEE International Workshop on Robot and Human Interactive Communication (IEEE Catalog No.04TH8759). doi:10.1109/ROMAN.2004.1374805.
Murakami Y, Kuno Y, Shimada N, Shirai Y (2001) Collision avoidance by observing pedestrians’ faces for intelligent wheelchairs In: International Conference on Intelligent Robots and Systems, 2018–2023.. IEEE, Maui, HI.
Pellegrini S, Ess A, Schindler K, Van Gool L (2009) You’ll never walk alone: Modeling social behavior for multi-target tracking In: International Conference on Computer Vision, 261–268.. IEEE, Kyoto.
Morales Saiki LY, Satake S, Huq R, Glas D, Kanda T, Hagita N (2012) How do people walk side-by-side?: using a computational model of human behavior for a social robot In: ACM, 301–308, Boston, MA.
Ferrer G, Garrell A, Sanfeliu A (2013) Robot companion: A social-force based approach with human awareness-navigation in crowded environments In: Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference On, 1688–1694.. IEEE, Tokyo.
Yamaoka F, Kanda T, Ishiguro H, Hagita N (2010) A model of proximity control for information-presenting robots. Trans Robot 26(1): 187–195.
Satake S, Kanda T, Glas DF, Imai M, Ishiguro H, Hagita N (2009) How to approach humans?-strategies for social robots to initiate interaction In: International Conference on Human-Robot Interaction, 109–116.. IEEE, La Jolla, CA.
Shi C, Shimada M, Kanda T, Ishiguro H, Hagita N (2011) Spatial formation model for initiating conversation In: Proceedings of Robotics: Science and Systems, Los Angeles, CA, USA.
Muller J, Stachniss C, Arras KO, Burgard W (2008) Socially inspired motion planning for mobile robots in populated environments In: Proc. of International Conference on Cognitive Systems, Germany.
Zender H, Jensfelt P, Kruijff G (2007) Human-and situation-aware people following In: Robot and Human Interactive Communication, 2007. RO-MAN 2007. The 16th IEEE International Symposium On, 1131–1136.. IEEE, Jeju.
Garrell A, Sanfeliu A (2012) Cooperative social robots to accompany groups of people. Int J Robot Res 31(13): 1675–1701.
Fussell SR, Setlock LD, Parker EM (2003) Where do helpers look?: gaze targets during collaborative physical tasks In: CHI’03 Extended Abstracts on Human Factors in Computing Systems, 768–769.. ACM, New York, NY, USA.
Staudte M, Crocker MW (2009) Visual attention in spoken human-robot interaction In: Proceedings of the 4th ACM/IEEE International Conference on Human Robot Interaction, 77–84.. ACM, New York, NY, USA.
Liu C, Ishi CT, Ishiguro H, Hagita N (2012) Generation of nodding, head tilting and eye gazing for human-robot dialogue interaction In: Human-Robot Interaction (HRI), 2012 7th ACM/IEEE International Conference On, 285–292.. IEEE, New York, NY, USA.
Lu DV, Smart WD (2013) Towards more efficient navigation for robots and humans In: Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference On, 1707–1713.. IEEE, Tokyo.
Takayama L, Pantofaru C (2009) Influences on proxemic behaviors in human-robot interaction In: International Conference on Intelligent Robots and Systems, 5495–5502.. IEEE, St. Louis, MO.
Ratsamee P, Mae Y, Ohara K, Takubo T, Arai T (2012) People tracking with body pose estimation for human path prediction In: International Conference on Mechatronics and Automation, 1915–1920.. IEEE, Chengdu.
Blanco José-Luis (2009) Contributions to Localization, Mapping and Navigation in Mobile Robotics. PhD. in Electrical Engineering, University of Malaga. http://www.mrpt.org/Paper:J.L._Blanco_Phd_Thesis.
Hall ET (1966) The Hidden Dimension. vol. 6. Doubleday.
Scandolo L, Fraichard T (2011) An anthropomorphic navigation scheme for dynamic scenarios In: International Conference on Robotics and Automation, 809–814.. IEEE, Shanghai.
Papadakis P, Spalanzani A, Laugier C (2013) Social mapping of human-populated environments by implicit function learning In: Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference On, 1701–1706.. IEEE, Tokyo.
Sato K (1992) Deadlock-free motion planning using the laplace potential field. Adv Robot 7(5): 449–461.
Trautman P, Ma J, Murray RM, Krause A (2013) Robot navigation in dense human crowds: the case for cooperation In: Robotics and Automation (ICRA), 2013 IEEE International Conference On, 2153–2160.. IEEE. doi:10.1177/0278364914557874.
Reeves B, Nass C (1997) The media equation: How people treat computers, television, and new media like real people and places. Comput Math Appl 33(5): 128–128.
Luber M, Stork JA, Tipaldi GD, Arras KO (2010) People tracking with human motion predictions from social forces In: International Conference on Robotics and Automation, 464–469.. IEEE, Anchorage, AK.
Ratsamee P, Mae Y, Ohara K, Kojima M, Arai T (2013) Social navigation model based on human intention analysis using face orientation In: Intelligent Robots and Systems (IROS), 2013 IEEE/RSJ International Conference On, 1682–1687. doi:10.1109/IROS.2013.6696575.
Pacchierotti E, Christensen HI, Jensfelt P (2006) Evaluation of passing distance for social robots In: International Symposium on Robot and Human Interactive Communication, 315–320.. IEEE, Hatfield.
Albaum G (1997) The likert scale revisited. J-Market Res Soc 39: 331–348.
Deb K, Pratap A, Agarwal S, Meyarivan T (2002) A fast and elitist multiobjective genetic algorithm: Nsga-ii. Trans Evol Comput 6(2): 182–197.
Zanlungo F, Ikeda T, Kanda T (2011) Social force model with explicit collision prediction. EPL (Europhys Lett) 93(6): 68005.
Acknowledgments
This work was supported by the Grant-in-Aid for Scientific Research (C) 23500242. We would like to thank all the participants who joined the experiments for their valuable work and comments. Special thanks to the anonymous reviewers for their valuable feedback that helped us improve the paper. This paper was presented in part at the IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, November 3 - 8, 2013.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
RP initiated the conceptual idea, implemented, conducted the experiments, gathered and analyzed data, and drafted the manuscript. YM helped to initiate the concept, provided facility and technical support, and helped to revise the manuscript. KM, KK, and HM provided technical advises, and helped to revise the manuscript. AT revised the concept, provided all support and advises, and helped to revise the manuscript. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (https://creativecommons.org/licenses/by/4.0), which permits use, duplication, adaptation, distribution, and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ratsamee, P., Mae, Y., Kamiyama, K. et al. Social interactive robot navigation based on human intention analysis from face orientation and human path prediction. Robomech J 2, 11 (2015). https://doi.org/10.1186/s40648-015-0033-z
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s40648-015-0033-z